



Yesterday Cisco released an advisory for CVE-2019-1663 – a pre-authentication code execution vulnerability in the RV110W, RV130W and RV215W router series. If you own one of the affected devices, check out that link for all remediation advice, including a new, patched firmware.
We were one of two parties who reported this to Cisco, and they’ve been extremely pleasant to disclose to. Here’s a quick root-cause analysis of CVE-2019-1663.
The device
While it affects a few other routers, we initially found this issue on the RV130. The RV130, like a lot of routers and other embedded IoT devices, does not run Cisco IOS. Instead it runs some form of embedded Linux. The majority of router-like functionality is handled by a small set of binaries which parse user input and make the router do useful router things.
Most of the user input comes through the web interface – which is where we found this bug. The affected binary is the “httpd” webserver binary. Although distinguished and Apache-sounding, in reality this is just a monster process handling pretty much everything that happens over ports 80/443. It takes user input over HTTP and transmutates this into system-level configurations. As with all embedded webserver binaries, it’s infinitely fascinating and behaves in some really weird ways sometimes (I spent a long time reverse-engineering it more out of interest than bug-hunting) – but that’s a story for another post. Let’s get into the mechanics of the problems behind CVE-2019-1663.
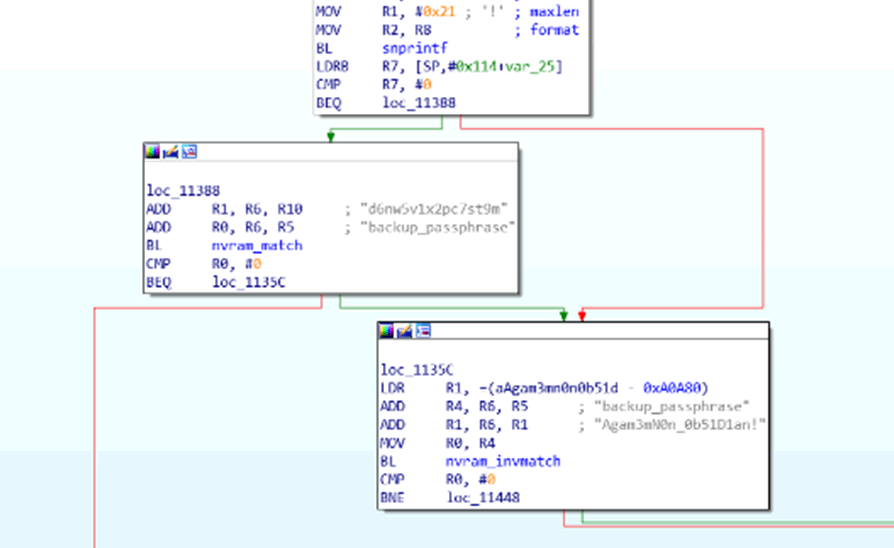
Figure 1 – This image is extraneous to the message of this blog post, but really, look at this cool string in the RV130 firmware.
The trigger
A buffer overflow happens if an overly-long value is passed to the “pwd” parameter at the login.cgi endpoint. This is, of course, before authentication. Let’s quickly do a “normal” login and follow the code path.
Login requests to the web interface are sent to the login.cgi endpoint in the following form:
POST /login.cgi HTTP/1.1 Host: 192.168.1.1 User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Referer: https://192.168.1.1/ Content-Type: application/x-www-form-urlencoded Content-Length: 137 Connection: close Upgrade-Insecure-Requests: 1 submit_button=login&submit_type=&gui_action=&wait_time=0&change_action=&enc=1&user=cisco&pwd=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA&sel_lang=EN
The “pwd” value sent is actually the 32-byte long “encoded” password, calculated by JavaScript in the browser just before the request is sent (for clarity when looking at memory, we’re just sending 32 “A“s in this example).
The login is handled by a function in httpd at 0x0002C614 (oh yeah, also, no PIE/ASLR in the binary). The request parameters are parsed from the POST request, tokenised and put in the executable’s static data store (the .bss segment).
Figure 2 – The parameters in memory after they’ve been pulled out of the POST request.
Then, the legitimate encoded password is pulled out of the device NVRAM and put in memory. Next, the value from the “pwd” parameter is pulled from the .bss segment and the standard C call strcpy is used to put it in dynamically-allocated memory.
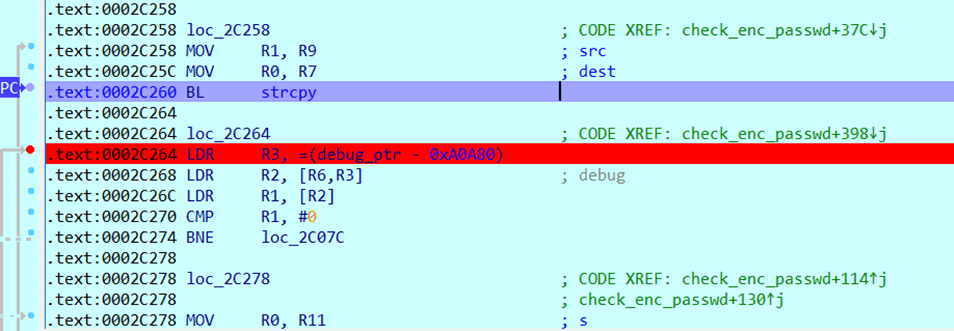
Figure 3 – *record scratch*.
Yes, that’s strcpy. We’ll get back to that in a second.
Under normal login conditions, each value is subject to the same scrutiny. After strcpy has copied the values into memory, strlen measures how long each item is, then (if they’re the same length) strcmp compares the two values. You get logged in if all these checks are passed.

Figure 4 – Better check those lengths eh?
Ok. So what’s the problem?
strcpy is bad
Why is strcpy bad? How can it be bad when it gets used so much?!
Figure 5 – strcpy is more common than you think. Get checked.
C programmers and security people will likely be rolling their eyes at this point. It’s well known – notorious, even – that strcpy is a dangerous function to use. There are literally thousands of articles about this function online, dating back decades, explaining why it’s dangerous. I’ll quickly paraphrase now.
Let’s look at the (latest free draft version of the) C standard. strcpy is defined like this (emphasis ours):
#include <string.h> char *strcpy(char * restrict s1, const char * restrict s2);
[…]
The strcpy function copies the string pointed to by s2 (including the terminating null character) into the array pointed to by s1. If copying takes place between objects that overlap, the behavior is undefined.
“The behavior is undefined” is an elusive way of saying “this might break something”.
strcpy is bad because it will copy a string (s2), right up until the null terminator, to the memory at the specified pointer (s1). No length is passed to the function. Look up there, is there a length parameter passed to strcpy? No, there isn’t. strcpy doesn’t care about the length of the string. For strcpy, the length of the string is entirely unimportant. The concept of a size is entirely alien to strcpy. When you’re using strcpy, you don’t tell it the length of the string, and no-one else does either. strcpy does exactly what it’s told and carries it through to the end no matter the obvious immediate consequences. My therapist might say strcpy lacks the capacity for critical or contextual reflexive action. It lacks the faculties which many people come to expect from writing other memory-safe languages. It’s unreasonable to use strcpy this year, “The Year of Our Lord” Twenty-Nineteen CE/AD. To use a phrase which will certainly carbon-date this post to somewhere in late 2018/early 2019: strcpy certainly “ain’t it, chief”.
Yes, a corporate blog post flogging a semi-popular meme as a shortcut to humour in their lazy copywriting. *checks watch*. It’s definitely 2019.
When you use strcpy (or one of the many, many other unsafe functions), you are riding the C bicycle without a helmet. And possibly without brakes. Some might also say, without a helmet, without brakes, but also with training wheels.
Sorry, yes, ok, so: you’re taking a pointer to a memory location you’ve previously allocated (and already declared a size for!), and you’re copying the string to that memory. Nothing will stop this string overwriting the bounds of the memory you allocated. That’s why it’s bad. And if someone else has control over the source string, you are giving an external entity the capability to overwrite the bounds of the memory that you allocated – which might mean they can overwrite something important with something bad. In most exploitable cases, this will mean overwriting a saved return pointer on the stack and redirecting the execution flow of the process.
Anyway, this is what will probably happen if you use strcpy:
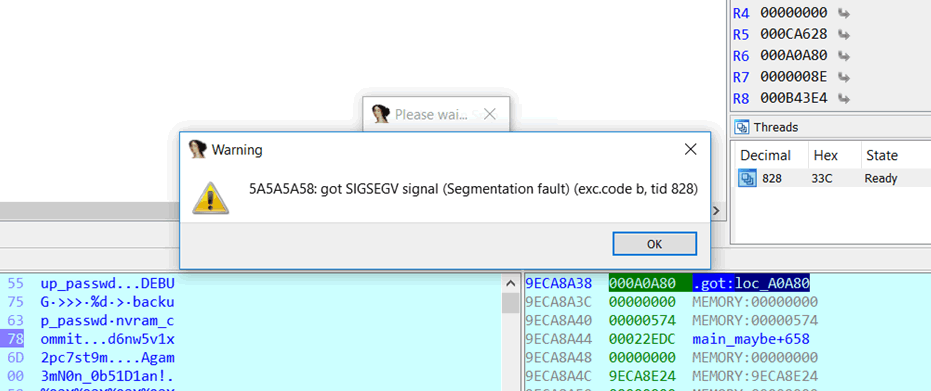
Figure 6 – A segfault ☹
In fact, that’s exactly what happens if you send the following request to the RV130:
POST /login.cgi HTTP/1.1
Host: 192.168.22.158
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://192.168.22.158/
Connection: close
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Content-Length: 571
submit_button=login&submit_type=&gui_action=&default_login=1&wait_time=0&change_action=&enc=1&user=cisco&pwd=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAZZZZ&sel_lang=EN
A saved return pointer on the stack is overwritten by our “ZZZZ”, so execution flow is redirected to 0x5A5A5A5A.
So what? Now I can’t copy strings? Security is ruining everything! Insert Linus rant here!
Well, no, that’s an overreaction. Also, if you have any feeling other than existential disappointment about strcpy being used in 2019, you’ve very late to the party.
You’ll often come across people recommending strncpy (with an “n”) instead of strcpy. In fact, you’ll often see a lot of strncpy if you’re RE-ing embedded webserver binaries. However, strncpy is also not ideal. While it does take a size parameter, it doesn’t always null terminate. Passing a string to strncpy which is longer than the size will write the string itself right up to the final byte, with no null terminator. Working with strings which you imagine to have been null terminated, but actually haven’t, could go wrong in quite unpleasant ways.
Luckily, there’s strlcpy (with an “l”). strlcpy is a nonstandard function which takes a third length argument, and always null terminates.
There are arguments articulated in mailing list archives that strlcpy being non-standard might cause compatibility issues. But there is literally zero reason for people who are shipping embedded devices not to use whatever functions they want – standard or nonstandard. You’re literally shipping tiny computers to people! The computers run whatever you want on them! Compatibility isn’t an issue! Use strlcpy!
Or, you know, don’t write C.







