



A significant part of reverse engineering and attacking devices relies on viewing and recognising data in various forms and working out how to decode it.
We typically use Linux tools and scripts to do this, but you can make the first few steps using a really neat online tool called CyberChef.
What is binary?
All data is stored as a series of 1s and 0s. A single 1 or 0 is called a bit. We call this binary because there are two values.
The next largest common unit is a byte, which is 8 bits.
Beyond this, SI prefixes are used. 1 kilobyte (kB) is technically 1000 bytes and 1 kibibyte (KiB) is 1024 bytes. However, kB is frequently used for both 1000 bytes and 1024 bytes, even in technical contexts. During most reverse engineering, kB means 1024 bytes.
| Unit | Size |
| kB (kilobyte) | 1024 bytes |
| MB (Megabyte) | 1048576 bytes or 1024kB |
| GB (Gigabyte) | 1073741824 or 1024MB |
To determine how many possible values can be stored in a data of a given length, you do the following calculation:
Values = 2^bits
^ means “to the power of”
For example, a single byte (8 bits) can store 2^8 or 256 values. 2 bytes (16 bits) can store 2^16 or 65536 values. Increasing the bit length by 1 bit will double the number of possible values.
You can see that by the time you have reached 64 bits, there are a huge number of possible values.
| Bits | Values |
| 8 | 256 |
| 16 | 65535 |
| 32 | 4294967296 |
| 64 | 1.84e19 |
| 128 | 3.4e38 |
The number of potential values can be important when calculating the search space for performing brute-force attacks.
Although there are 256 values in a byte, the values normally start at 0. Therefore, the range is 0-255, covering all 256 values.
Binary data can encode information in many different forms. The following are all representations of the same data
- 01000001 (binary)
- 65 (decimal)
- 41 (hexadecimal)
- A (ASCII or text)
- QQ== (base 64, a means of encoding binary as text)
What is hexadecimal? Well, instead of each digit representing 10 values (0-9 as in decimal), each digit represent 16 values (0-15). Clearly we can’t put 15 into one digit, so we use letters above 9.
| Hex | Decimal |
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| A | 10 |
| B | 11 |
| C | 12 |
| D | 13 |
| E | 14 |
| F | 15 |
As a single hex digit represents 16 values, this is only 4 bits (2^4 = 16). To represent a byte, we need to use 2 hex digits such as D4 or 8E.
We will frequently use the prefix of 0x to represent hex i.e. 0x41. Context is everything though – never assume how data is encoded! It can be text, part of a floating point number, or code.
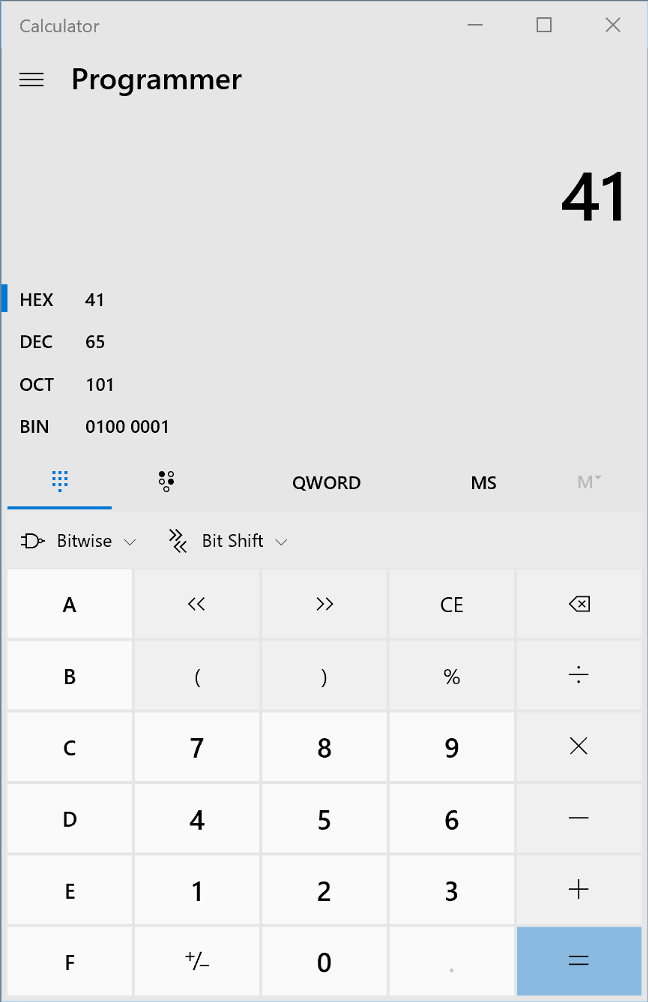
You can use the built-in calculator in Windows and OS X to convert from one to the other if you switch to programmer view:
Onto CyberChef
A useful tool for many of these understanding data is called CyberChef. This is an online tool that runs entirely in the browser. None of the data entered leaves your machine, and it can be saved and run locally.
Yes, it’s GCHQ. No, they aren’t stealing your secrets. At least not using this tool.
Multiple operations can be chained together to form a pipeline. This includes simple conversions, but also complex things such as encryption and decryption.
Let’s start my putting some text into the “Input” section. This will be copied verbatim to the “Output” section as no “Recipe” has been created.
On the list of “Operations” on the left hand side, drag “To Hex” into the “Recipe”. The output will now show a hexadecimal representation of the text.
You can search the operations using the box on the top left rather than hunt through all the subsections.
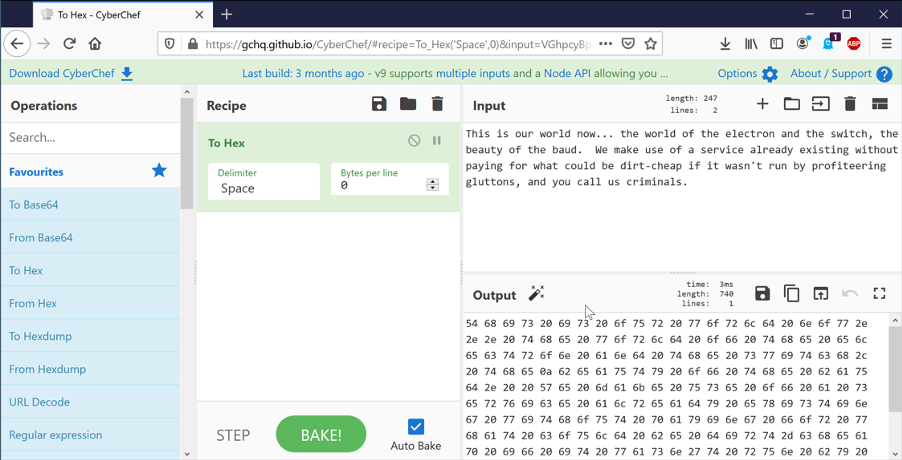
The text is encoded using a method called ASCII. Each character is represented by a single byte. In reality, only 7 of the 8 bits in the byte are used, giving 128 (2^7) possible characters.
Converting to and from ASCII is a very common task. Tables showing all the values are available online.
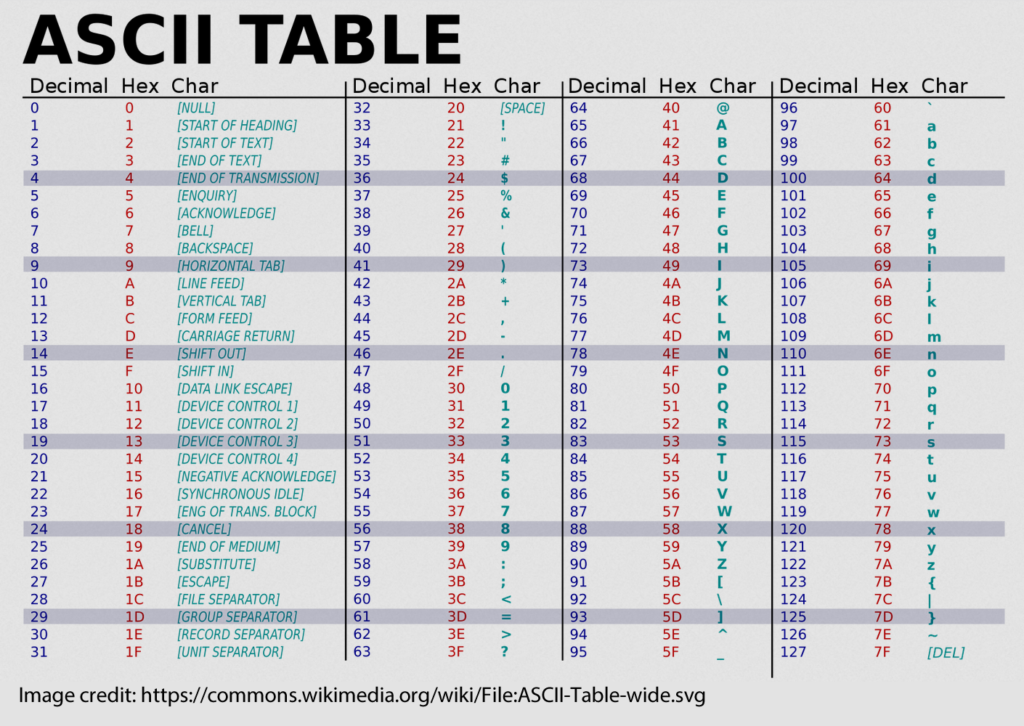
Ranges and values worth becoming familiar with are:
- 0x20 – space
- 0x30-0x39 – 0-9
- 0x41-0x5A – A-Z
- 0x61-0x7A – a-z
It’s very common for the value of 0x41 – capital A – to be used when performing tests for buffer overflows. You’ll start to recognise long strings of 41414141 when looking at memory!
ASCII is not the only way of encoding text. Unicode is a common format that allows many more possible characters, but there are tens of different encodings. You can use the “Text encoding” operation to see these. UTF-16LE encodes each letter as 2 bytes (the 16 means 16 bits). Now each second character looks like a “.”.
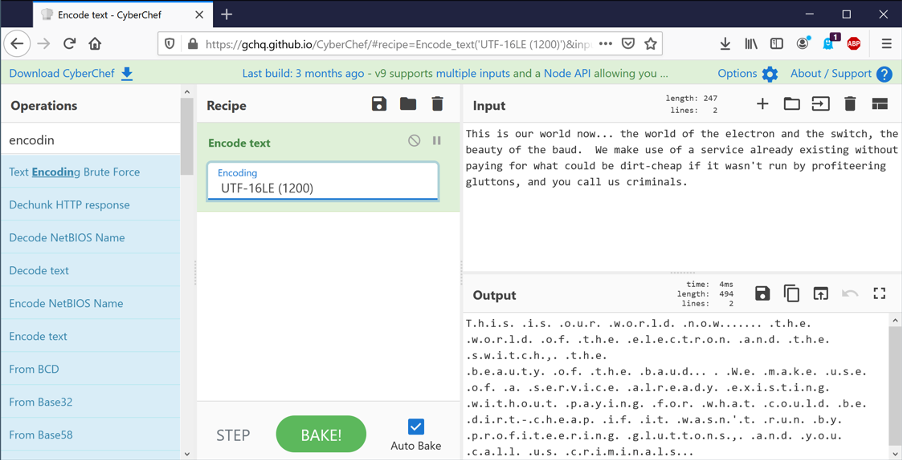
If we now add the “To hex” operation, we can see that every second byte is 0x00 – a null. Those “.” just mean “I’m not sure how to display this”.
We can flip this round and firstly take hex, convert it to binary using “From hex”, and then decode the text using “Text decode”.
You can click this link to see this directly.
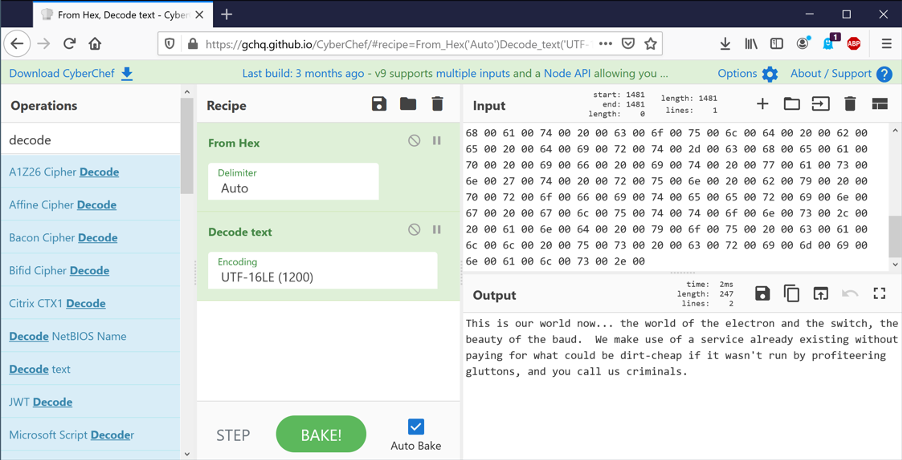
If we use the correct encoding, (UTF-16LE), then the text looks as expected. Change it to UTF-16BE though, and suddenly we have nonsense.

This is a vital point – binary data can be interpreted in many different ways. Our operating systems and programs use file extensions and metadata to determine how to handle the content, but as reverse engineers we often need to guess.
So far we have just looked at text. However, executables on our machines are also just binary data. We can load these into CyberChef and analyse them.
I have chosen to look at write.exe from C:\Windows\system32\ – it’s small enough that CyberChef can handle it but provide some interest.
You’ll immediately see some recognisable strings. Nearly all executables will have these in some form. They can be incredibly useful in reverse engineering software, allowing us to determine function, endpoints, passwords and more.

Another operation called “Strings” will filter out lengths of text longer than a certain limit. As you can see, it matches some data that is not text – this is just where binary data happens to decode as ASCII correctly.
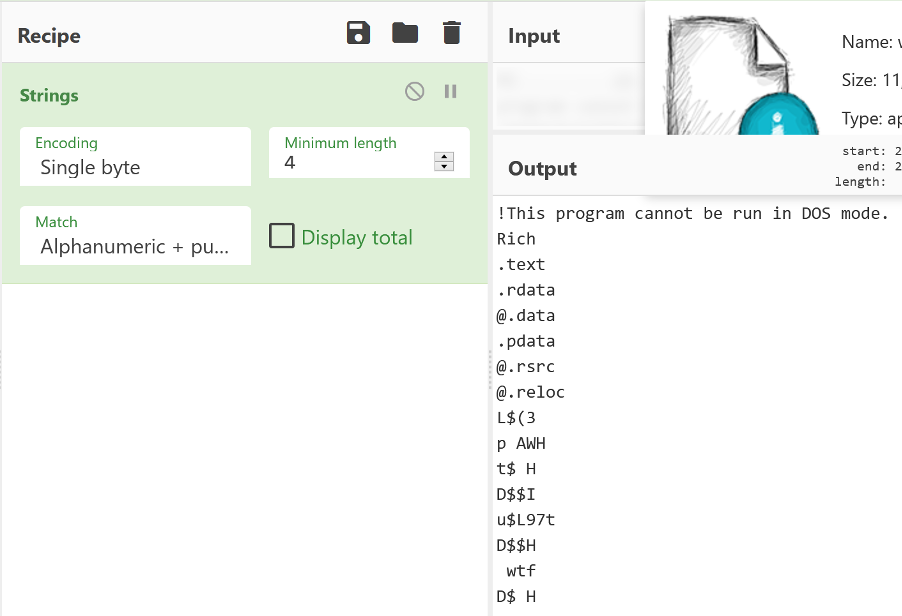
We know that this is a Windows executable as we just read it from our own system. The .exe on the end is just part of the filename – it would still be the same binary data if it was called cheese.txt.
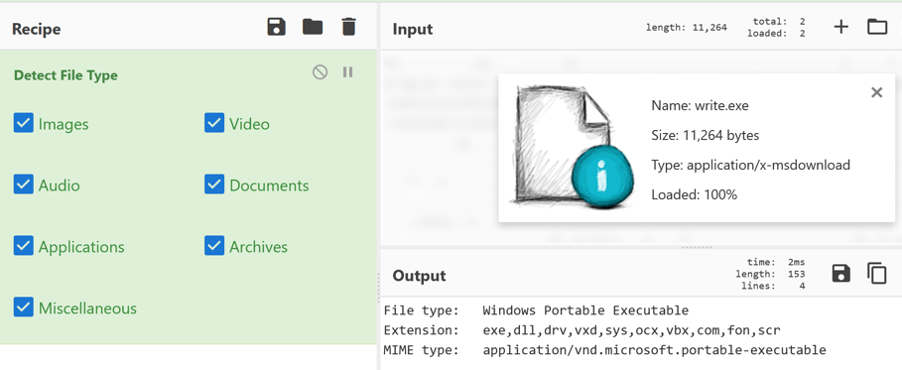
But frequently, we don’t actually know what a file is actually meant to do – is it an executable? A zip file? An image?
CyberChef has the operation “Detect File Type”. This fingerprints the file and gives you a best guess as to what it is. It’s not infallible, but it is helpful.
Let’s analyse a slightly longer text file of words.
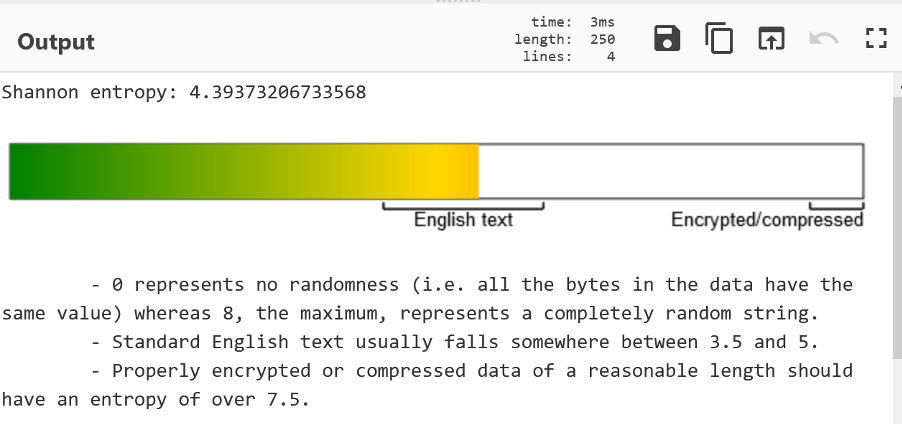
Add the operation “Entropy”. What this does is look at the “randomness” of a file. By default, this uses something called Shannon entropy calculated across the whole file. Data in the middle ground has structure – it’s either text, an executable, or some other form of information.
Another useful tool to determine file content is “Frequency Distribution”. This counts how often given byte values occur across the file. Frustratingly, the lower axis in in decimal not hex, but you can see some clear spikes. The very high one – at 32 – is 0x20 or space. The cluster around 107 are lowercase characters.
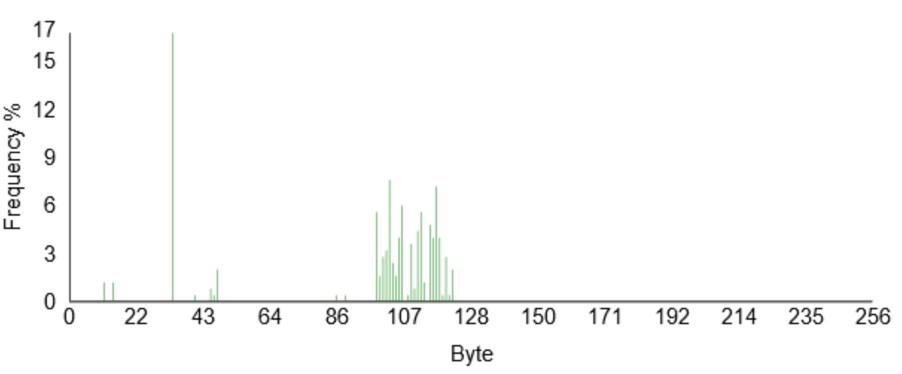
Now try the same with write.exe and a zip file (>10Kbytes or so).
You’ll see that write.exe actually has entropy similar to text – despite it not being text. It has structure however and does contain some text. The frequency distribution is quite different though!
I’ve added another operation – remove null bytes – so that the huge number of 0x00 in the file are removed from the graph to make it more clear.
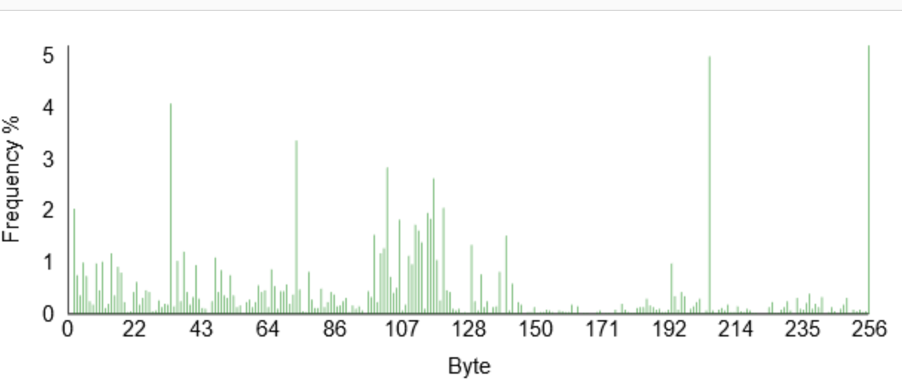
You can see the same “bump” around 107 – this is the text embedded inside the executable. But there is a much wider spread of values than with the text file.
The zip is a different story though. The Shannon entropy is 7.99 out of 8. It’s as random as it could be. This is nearly always a sign of compression or encryption. Nearly all compression works by spotting patterns and condensing them down – hence the structure is removed. Encrypted data should be indistinguishable from random noise.
This is a zip file – so the compression results in high entropy.

When we look at the frequency distribution, we can see a much more uniform distribution across all values. Again, a sign of compression or encryption. These are handy tools to determine what is in a file, especially firmware and the like.
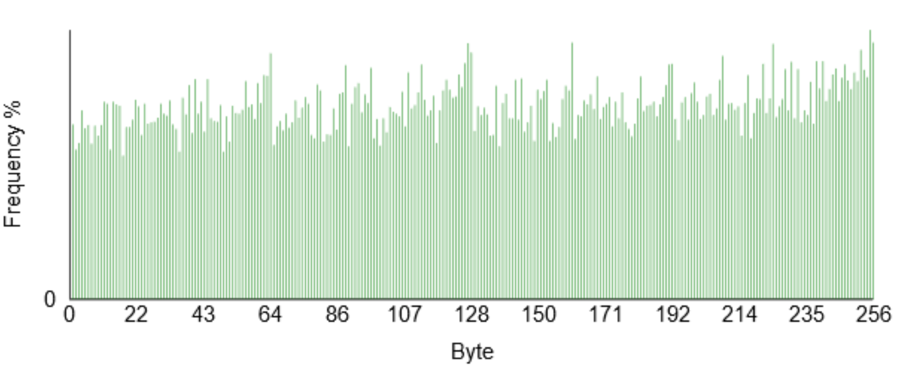
To demonstrate this, you can encrypt a file using AES in Cyberchef and check the entropy and frequency distribution.
You can click this link to see the operations required.

Conclusion
I hope this introductory post helped you to understand binary and some of the tools we can use to convert, decode, and understand the purpose of various data.
Note: This post was originally published here.







