


After the VTech hack, we thought we’d have a look at the security of some of their devices, just to see what we could find and whether I would even think about giving one to my kids.
So after further messing around with our online shopping recommendations, we ordered some of their devices. Ken took the back off one, discovered that the CPU was our old friend RockChip and that for some reason it used a micro-SD card to store its data.
I have taken apart a lot of tablets, both hi-spec ones designed for game playing and cheap ones designed for children to use. I have never seen an SD card being used to store the OS. This makes it very easy to extract the contents of the device’s memory and tear it apart offline. You can even do this with five minutes of alone time with the tablet.
I’m going to explain how we can do about doing this.
The first step is the easiest: Image the device. This is best done from Linux through a card reader and can be performed by using the dd command to directly copy from the block device for the card reader to a file.
We then end up with an 8 GB binary data file. How do we process this? Those of you that have read my previous posts are probably thinking “binwalk”. Usually, yes, but not this time. You can binwalk it, but you will get a lot of false positives and false leads. We’re going to be sneakier.
Now we know that the device is:
- Running Android
- Is based on the Rockchip CPU
This gives us an idea of some common partitions (cache, system, data) and how the bootloader work (using a parameter block which defines the partitions when passed to the Linux kernel).
So, as a sanity check and to help us out later, we can use the strings command – the command will return anything that looks like a NUL terminated string and search for the parameter block:
/PARM
FIRMWARE_VER:4.1.1
MACHINE_MODEL:rk30sdk
MACHINE_ID:007
MANUFACTURER:RK30SDK
MAGIC: 0x5041524B
ATAG: 0x60000800
MACHINE: 3066
CHECK_MASK: 0x80
KERNEL_IMG: 0x60408000
#RECOVER_KEY: 1,1,0,20,0
CMDLINE:board.ap_mdm=0 board.ap_has_earphone=1 board.ap_has_alsa=0 board.ap_multi_card=0
board.ap_data_only=2 console=ttyFIQ0 androidboot.console=ttyFIQ0 init=/init initrd=0x62000000,
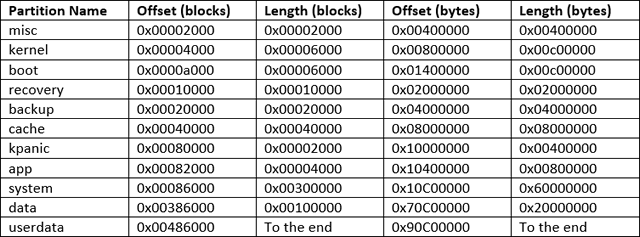
0x00800000 mtdparts=rk29xxnand:0x00002000@0x00002000(misc),0x00006000@0x00004000(kernel),
0x00006000@0x0000a000(boot),0x00010000@0x00010000(recovery),0x00020000@0x00020000(backup),
0x00040000@0x00040000(cache),0x00002000@0x00080000(kpanic),0x00004000@0x00082000(app),
0x00300000@0x00086000(system),0x00100000@0x00386000(data),-@0x00486000(userdata)
Got it! This tells us that there isn’t anything funny going on with the image, it is where the boot media is stored and the locations of the partitions (well, the locations with an offset that the boot loader knows about):
0x00006000@0x0000a000(boot),0x00010000@0x00010000(recovery),0x00020000@0x00020000(backup),
0x00040000@0x00040000(cache),0x00002000@0x00080000(kpanic),0x00004000@0x00082000(app),
0x00300000@0x00086000(system),0x00100000@0x00386000(data),-@0x00486000(userdata)
So those numbers are all the offsets in hexadecimal that the partitions are placed at. The offsets are in blocks, so we need to multiple each number by 512 (0x200 hex). The format is <length > @ <offset> (name).
We can sort this by offset and translate from blocks to bytes:
Unfortunately we need to know the offset of the boot in the image. We could work this out from the parameter block, but the Internet doesn’t provide much information about these at all. There’s one more thing we can try.
We can try looking for known data and track it back to the start of the partition. Then we can assume the offset is consistent.
As the device is Android over version 4.0 we know that at the very least the cache, system and userdata partitions with be using the ext2 or later file systems. This gives us an avenue of attack: we can loop through the image and search for things that look like an ext2 file system.
This isn’t immediately easy: we have an 8 GB image and 3 – 4 different files systems in there, so how can we find at least one so that we start finding the other filesystems?
Ext2 (and later) file systems have something called the superblock that is a block at a specified place in the file system that is used to define the parameters for the file system. This superblock is replicated through the file system as a safety measure in case the original one gets corrupted.
We can easily find the format for the superblock thanks to the wonders of open source. From this we know it is placed 1024 bytes (0x400) from the start of the filesystem and the rough structure.
The superblock has a magic number – a number which should identify the data – of 0xEF53 (you can read that as EFS 3 if you want), but a quick experimentation showed me that that would produce a lot of false positives, so I needed slightly more to minimise this.
Upon a bit of delving, the structure has some fields, s_state, s_errors and s_creator_os, that are guaranteed to be small. So if we find a block of data with the magic number in the right place and the above fields less than a certain value we’re pretty certain we have a superblock. In C, this would be:
superblock.s_state < 3 &&
superblock.s_errors < 4 &&
superblock.s_creator_os < 5)
So I wrote a quick bit of C, which I’ve uploaded to our github. Note, this is quite hacky and inefficient C and I wouldn’t use it in anger.
Compiling and running this (and waiting for a while) found a number of potential superblocks, most of them were duplicates (remember that bit I said earlier about superblocks being spread throughout the filesystem for a backup):
Possible superblock at 8400400: /cache
Possible superblock at 8414400: /cache
Possible superblock at 841f400: /cache
Possible superblock at 8425400: /cache
Possible superblock at 882e400: /cache
Possible superblock at 8833400: /cache
Possible superblock at 883b400: /cache
Possible superblock at 884a400: /cache
Possible superblock at 11000400: /system
Possible superblock at 19001000:
Possible superblock at 29001000:
Possible superblock at 39001000:
Possible superblock at 411a0400: /system
[…]
And there was more, but we already have enough now. Let’s look at the first finding: /cache at 0x8400400, which is the start of the superblock, which means the file system starts at 0x8400000. Looking to the table above, we can see that according to the parameter block, the cache partition should start at 0x08000000, which means that the offset is:
Or in reality, it just means that we can add 0x00400000 to every file offset to find it. So this means that the userdata partition is at 0x90C00000 in the parameters file, so it must be at:
…in the image file. So we can extract it. The quickest way to do this is to use the old faithful dd command, using something like:
But this would take about 8 hours to work as we setting it to use a blocksize of 1 byte – doing it would read the file in one byte at a time and then write it out to the destination one byte at a time.
We can speed this up, by increasing the blocksize by using bash expressions, inside a $(( )) brackets. If we make the blocksize a multiple of the offset, then we don’t need to mess around here. My virtual machine only has 1 GB of memory so I can’t make the blocksize the whole offset, but if I divide it by 4 and then skip 4 blocks it will all magically work out:
skip=4
9+1 records in
9+1 records out
5636096000 bytes (5.6 GB) copied, 421.829 s, 13.4 MB/sreal 7m2.643s
user 0m0.004s
sys 0m25.575s
Now we can just mount this volume on a convenient mount point and we can access the userdata partition, which will contain all changeable aspects of the device, including the accounts database, the wireless configuration and the apps’ sandboxes!
app cameraKeyStatus.txt gsensorcal nandCartridgeStatus.txt
app-asec dalvik-cache local property
app-lib data lost+found resource-cache
app-private dontpanic media ssh
backup drm media_profiles.xml system
bluetooth gps misc user







