



TL;DR
- The belief that OT networks are too fragile to test is an oversimplification. Most of the devices where the real security risk sits are robust enough for conventional testing techniques.
- A staged, risk-averse methodology lets us start with zero-risk techniques and progress only when devices have been shown to tolerate them.
- Whether a system is operational or in shutdown changes what we can test, but not how carefully we work. Planned outages open up deeper testing.
- The real risk is choosing not to test at all, leaving security weaknesses in place for an attacker to find instead.
Introduction
There is a widely held belief that penetration testing Operational Technology networks is impossible. That simply connecting a laptop to a network will take down everything. That running nmap will take down a factory. That the only safe approach is to not test at all.
This belief is wrong. Or rather, it is a massive oversimplification of a much more nuanced reality.
We have been testing OT networks for years across gas, electricity, water, maritime, and manufacturing. We test live systems controlling real processes. And we have a methodology that lets us do this without causing harm. Not because we are lucky, but because we understand what is actually sensitive and what is not.
The anecdotes are not the whole story
Everyone in information security has heard the stories. Someone ran a vulnerability scanner against a PLC, it fell over, and that caused a cascading failure resulting in plant shutdown. An IP address conflict on a tester’s laptop stopped a heartbeat mechanism working, causing the entire SCADA system to fallover. Some of these are real. Some are apocryphal. Most have been retold so many times that the details have shifted beyond recognition.
But they are not inevitabilities. They describe what happens when someone uses IT testing techniques against OT devices or without understanding the environment or doesn’t take suitable precautions. They do not prove that OT testing is impossible. They prove that doing it badly causes problems.
The memes and conference war stories have created an industry-wide assumption: OT networks are too fragile to test. This has become a convenient excuse for not testing at all, which leaves these systems with security weaknesses that nobody is looking for.
Not everything is fragile
The devices that tend to be genuinely sensitive to scanning and testing are at the lowest levels of the network – field devices. PLCs, RTUs, Safety Instrumented Systems, and some older embedded devices can behave unpredictably when they receive unexpected traffic. This is real. We take it seriously.
But these are not the devices where the most significant security risk usually sits. We know that if we gain network access to these devices we can either cause them to operate or stop them from working.
The bigger risks are in the devices that bridge the layers of the network. Firewalls, remote access gateways, data historians, engineering workstations, jump hosts. These are the devices an attacker needs to compromise to reach the process layer. And in our experience, they are almost always robust enough to withstand conventional testing techniques.
A firewall running a full OS and a web management interface is not going to crash because you connected to port 443. An engineering workstation running Windows is not going to brick because you checked what services it is running. These are the same types of systems that get tested in IT environments every day.
The question is not “can you test OT?” but “what can you test, and how?”
We know what is safe to touch
Over years of testing, we have built up a detailed understanding of which protocols, services, and device types tolerate testing and which do not.
ARP and ICMP are safe on every Ethernet device we have ever tested. We have never caused a problem with an ARP scan or a ping sweep at an appropriate speed. Web services on ports 80 and 443 are safe to connect to. SSH is safe to connect to. These are services that the devices are designed to accept connections on. Even the oldest, most dodgy device will accept a single connection to the web server it is running.
We have learnt the protocols and devices that are genuinely fragile. Some serial device servers will forward unexpected traffic to a serial bus if you do a version scan on the appropriate ports. Some IEC 61850 networks are extremely intolerant of additional traffic. Some very old PLCs have limited TCP/IP stacks that can be overwhelmed. We know which ones. We identify them early and we work around them.
For everything else, we start with the lowest-risk techniques. Passive traffic capture, ARP scanning, ping sweeps, targeted port scans on known-safe ports. We watch for signs of problems before progressing. If a device tolerates that, we move to service enumeration, web testing, and credential testing. If it won’t tolerate it, we stop and we find another way.
Operational state changes everything
The risk profile of a test is not just about the devices and techniques. It depends heavily on the operational state of the system at the time of testing.
A system that is fully operational and controlling a live process demands the most caution. Every technique has to be assessed against the possibility that it disrupts something that is actively keeping a process running, a valve open, a pump cycling, or telemetry flowing to a control room. This is where the staged methodology earns its keep. We are at our most conservative when the process is live.
A system in shutdown or outage is a different proposition. The process is not running, so the consequences of disrupting a device are far lower. A PLC that reboots during a planned shutdown is an inconvenience. The same PLC rebooting during production could be a safety event. Scheduled outages and maintenance windows are valuable opportunities to test devices and networks that would be off-limits during normal operation. We can be more aggressive with techniques, test deeper into the control layer, and interact with devices we would otherwise leave alone.
But shutdown does not mean anything goes. The system still needs to come back up cleanly. Configurations must not be altered. Firmware must not be changed. Anything we touch has to be left exactly as we found it, because the next time that system starts, it needs to work. Pre and post checks are just as important during a shutdown test. The difference is in what we can test, not in how carefully we work.
We’ll work with you to give you the most effective test with the days you can offer us.
The staged approach
Our methodology is staged and risk-averse. We progress through tiers of techniques, only moving to the next level when we have confidence that the target can handle it. Here is what each tier looks like in practice.
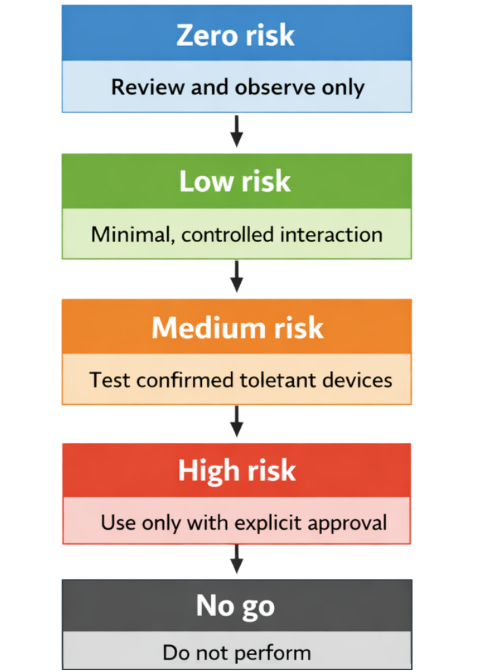
Zero-risk techniques. These carry no risk to the system and are always the starting point. Documentation and architecture review. Configuration file review of firewalls, routers, and switches. Visual site survey. Passive monitoring on a client-provided span or mirror port. Examination of downloaded files such as manuals, firmware images, or configuration tools. And probably the most important one – speaking with the people who work with these systems.
Low-risk techniques. These involve minimal interaction with the live network. Passive ARP sniffing and active ARP scanning at a controlled rate. Ping sweeps. Limited TCP port scans on known-safe ports (22, 80, 443). Using a DHCP-assigned or client-provided IP address. Interacting with an HMI without the intent of causing action or breaking out. Using built-in Windows network tools on an unlocked machine.
Medium-risk techniques. These are used against devices we have already confirmed can tolerate them. Full TCP port scans at a controlled rate. Version and banner grabbing. Direct Ethernet network interception on devices we know can be disconnected. Connection to physical serial consoles. Manual web application testing. Limited testing of known or default credentials against SSH, telnet, web interfaces, or Windows services. Attempting to break out of an HMI to the underlying operating system.
High-risk techniques. These are only used where the impact is understood and explicitly agreed with the client. Power cycling a device. Removal and reading of removable storage media. Password recovery mode on networking equipment. Use of known exploits. Brute force testing of multiple passwords. Altering a device configuration with the ability to revert.
No-go techniques. Vulnerability scanning with tools like Nessus. Automated web application scanning. Fuzzing or automated testing of unknown services. ARP spoofing. Use of new or untested exploits. Firmware updates or backdooring. Factory resets. Altering a configuration without the ability to revert. Use of malware.
This is not a theoretical framework. It is what we actually do on every engagement. Every technique against every device gets a risk assessment before we use it. We consider the impact if something goes wrong, the likelihood of it going wrong, how we would detect it, and how we would recover.
For the really sensitive systems we will discuss and risk assess this formally with the client ahead of time.
Systems we won’t touch
There are some systems we simply will not test while they are live. Safety Instrumented Systems that are actively protecting a process are off limits. IEC 61850 GOOSE traffic coordinating protection in a live substation is off limits.
Any system where the client or site contact tells us that disruption could cause an immediate safety impact is off limits. This is often something we want to dig deeper into. Why is that specific system so sensitive, and can an attacker trigger the same failure?
If it needs testing, we find another way, whether that is a maintenance window, a test environment, or bench testing in the lab.
Process knowledge matters
None of this works in isolation. We work closely with the client’s site staff throughout every engagement. They know what happens if a device restarts. They know which systems have fallen over in the past. They know which network link is carrying critical telemetry.
Before we start testing, we agree no-go devices, no-go networks, and no-go techniques. We agree pre and post checks so we can verify that nothing has changed. We establish communication paths to the control room, the SOC, and anyone else who needs to know what is happening.
If anything unexpected occurs, anyone can call a stop. The PTP lead consultant, the site contact, the control room. Testing would stop and would not resume until the cause is understood.
Although we’ve been requested to stop many times, we’ve not yet been the cause of the failure. We’d rather people were over cautious. But remember, the pen tester always gets the blame.
The real risk is not testing
The alternative to careful, risk-managed testing is no testing at all. And that is not a safe position. There has to be a balance between the safety of not testing and the risk of not knowing the vulnerabilities in your systems.
OT networks have security weaknesses. Breakglass access accounts with bad passwords on firewalls. Undocumented remote access gateways. A patch cable that means that the segmentation between IT and OT has been undone. Engineering workstations with direct internet access. These are the kinds of issues we find regularly, and they are the kinds of issues that an attacker would exploit.
If nobody tests, nobody finds these problems. They sit there until someone with less caution and less understanding of the environment finds them instead.
For the components where live testing is too risky or they are vital to security, there is another option. We can test it on the bench in a lab. This lets us use the techniques that would be unacceptable on a live system: physical teardown, connecting to internal serial ports, aggressive fuzzing. We can find out exactly how a device works without any risk to the process it would control in the real world. The results from this feed directly back into the implemented system, giving the client evidence of what an attacker could do to their specific hardware without the risk we cause significant disruption.
We test OT networks because it is the responsible thing to do. We do it safely because we have spent years learning how. The “you can’t test” memes are entertaining, but they should not be the basis for security strategy.







